Article Generator - BitPost 30 Day Challenge Day 25
Note
This article is from the BitPost 30 Day Challegne and was orignally posted there
Yesterday I posted an article titled No humans were harmed in the making of this article that was generated by an AI. If you read that post you will know that it was basically gibberish, and today I wanted to talk about how I created the program to do this and why the results are subpar. There is a lot to cover so today I am just going to go over the process at a very high level and the following days I will dig into more detail.
I uploaded the code I used to create this to a GitHub repository if you would like to look at it.
To create the article I used a GPT like model to produce a sequence of words of a specific length given an input sentence, in my case this was the title of the article. GPT uses a method called auto-regressive language generation that assumes the probability distribution of a sequence of words can be decomposed into the product of conditional probabilities of the next word distribution. Which in plain english means that we can generate text by using a sequences of words to estimate the most probable next word for that sequence. A mathematical formulation of this is given below:
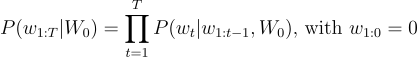
Where W_0 is the initial context word sequence (for me the title), T is length of the word sequence and is usually determined on-the-fly (This is not the total length of the article just the length of the current sequence). The probabilities of words need to be learned by the model during training, but I will be talking about that in a later article.
Now that we have a basic idea of what the model is doing, how do we actually choose the words? The naive solution is to use a Greedy Search, which just uses the highest probability word as the next word in the sequence. The issue with this is that while you are always choosing the highest probability word, you will most likely not choose the highest probability sequence of words. Here is a good visualization of the Greedy Search algorithm.
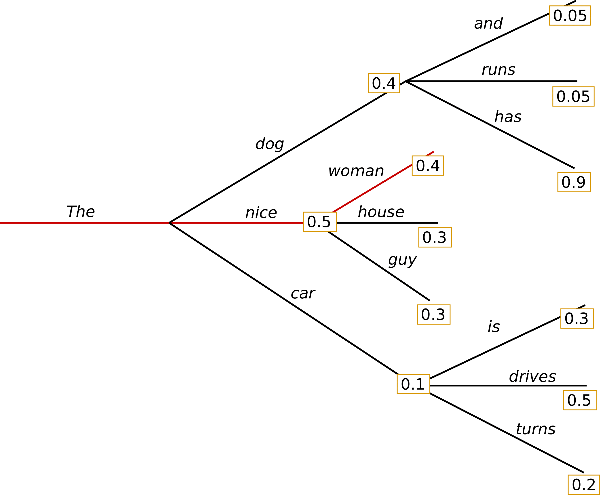
To give an explanation as to why this is not the best method lets look at a few paths on the tree. The path that the Greedy Search will take is highlighted in red and has an overall probability of 0.5 X 0.4 = 0.2 but if we look at the branch containing dog and has we get a total probability 0.4 X 0.9 = 0.36 which is a higher total probability than the chosen path so we need to use a different searching method.
A variation on the Greedy Search called Beam Search is often used instead, this is were we choose a number of "beams" to do a Greedy Search. Meaning we search through the top n most probably paths before choosing the most probable one. An illustration for an n=2 Beam Search is shown below for the same tree we used earlier.
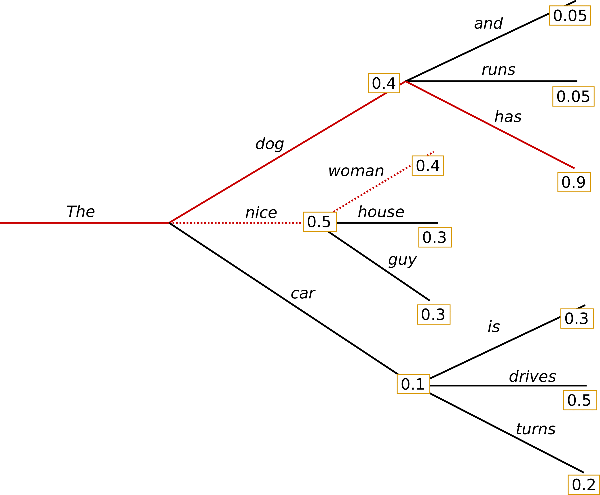
As you can tell this time we did actually get the most probable sequence, but if we used this for text generation we would run into a few issues. For starters let me show you the output of the same model using a Beam Search algorithm and the solution that I ended up using to create yesterdays article for the same input sequence. Given the sequence "I like to run", the Beam Search output was:
I like to run, I like to run, I like to run, I like to run, I like to run, I like to >run, I like to run, I like to run, I like to run, I like to run,
And with the solution used yesterday the output is:
I like to run my own station, and get them my way," Reeves said.
Canarias (Round Rock) resident Jason James Cox said he's much happier with the >program he's gained as a result of her visit.
Clearly the output on the bottom seems much more human like (albeit still a bit incoherent), but the top has a major flaw in that it just keeps repeating the same sequence. This is because given a specific sequence the Beam Search has a deterministic output meaning there is only one possible output for a specific input. We could help this by introducing penalties to the probability of words and sequences that have already been used, a simple implementation of this is to use n-gram penalties which sets the probability of an n-gram to 0 after it has already been used.
Using the same Beam Search algorithm as before but adding n-gram penalties we get the output below. Note : an n-gram is a grouping of n number of words, so in the sequence "The dog walks" the 2-grams are "The dog" and "dog walks"
I like to run, but I don't know how to do it," he said. "I'm not sure if I'm going >to be able to get out of here."
He said he has no idea if he'll ever get to
This is clearly a better output than what we had for the earlier Beam Search but there is still a big underlying issue with this method and that is when you want to produce an article that does have some repetition. Say for example you are writing an article on "The Supreme Court" and have decided that you will not repeat any 2-gram sequences then your article will only ever include the term "Supreme Court" once, which is obviously undesirable.
The solution I ended up using is something called Top-p (nucleus) sampling. This is the idea of sampling the top n number of words, where n will be decided on-the-fly such that the cumulative probability of all the words select is greater than or equal to some probability p. We then randomly select a word from the subset we just created with weighted likelihood based on the adjusted probabilities of each word in this subset (adjusted means that we keep the ratios of the probabilities for each word in the chosen subset the same but they are adjusted so that the cumulative probability of the subset will be 100%).
Tomorrow I will talk more about the actual model architecture to use for this kind of task and how we train a model like this.
Thanks for reading
Zach